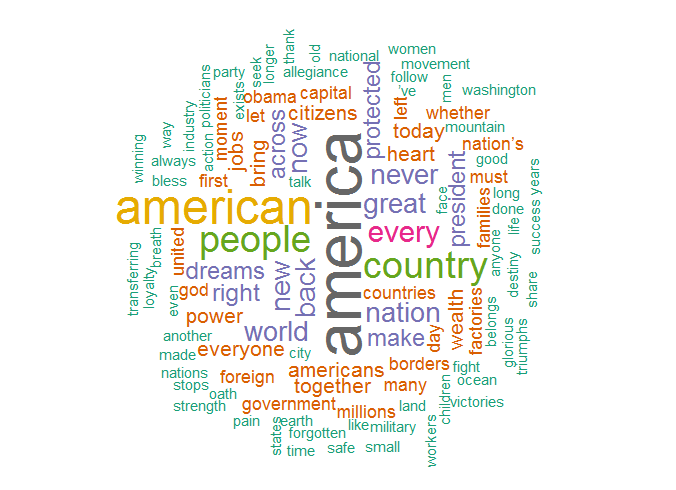
Eine Word Cloud visualisiert die Häufigkeit von Wörtern in einem Text
Eine Word Cloud oder Wortwolke ist eine gute grafische Möglichkeit, einen Text hinsichtlich von Worthäufigkeiten zu analysieren und somit thematische Schwerpunkte zu erkennen und zu visualisieren.
Die erste Schlagwortwolke wurde vermutlich 2002 von Jim Flanagan eingesetzt zur Visualisierung der Häufigkeit von Suchbegriffen. Je häufiger ein Wort in einem Text vorkommt, desto größer wird es in der Word Cloud dargestellt. Das R-Package wordcloud macht die Programmierung, Darstellung und Anpassung einer solchen Word Cloud zum Kinderspiel. Das Beispiel verwendet als Text die Antrittsrede von Donald Trump. Sie lässt sich hier als Text-Datei herunterladen.
library(tm)
library(wordcloud)
library(RColorBrewer)
data <- "https://www.petitessen.net/wp-content/uploads/2017/02/trump.txt"
text <- readLines(data)
doc <- Corpus(VectorSource(text))
toSpace <- content_transformer(function (x , pattern ) gsub(pattern, " ", x))
doc <- tm_map(doc, toSpace, "/")
doc <- tm_map(doc, toSpace, "@")
doc <- tm_map(doc, toSpace, "\\|")
doc <- tm_map(doc, content_transformer(tolower))
doc <- tm_map(doc, removeNumbers)
doc <- tm_map(doc, removeWords, stopwords("english"))
doc <- tm_map(doc, removeWords, c("get", "one", "say", "said", "can", "don’t", "going", "will"))
doc <- tm_map(doc, removePunctuation)
doc <- tm_map(doc, stripWhitespace)
# doc <- tm_map(doc, stemDocument)
tdm <- TermDocumentMatrix(doc)
m <- as.matrix(tdm)
v <- sort(rowSums(m),decreasing=TRUE)
df <- data.frame(word = names(v),freq=v)
set.seed(1001)
wordcloud(words = df$word, freq = df$freq, min.freq = 2,
max.words=200, random.order=FALSE, rot.per=0.35,
colors=brewer.pal(8, "Dark2"))
Das Skript: Die benötigten Packages sind tm für das Text Mining, wordcloud für die Erzeugung der Word Cloud und RColorBrewer, um die Wörter einzufärben. Dann liest das Skript den Text ein und weist ihn der Variablen text zu. Die Funktion Corpus() wandelt den Text um in Einen Corpus, der dann in der Variablen doc gespeichert wird. Ein Corpus ist der Textkörper einer Textsammlung. Der nachfolgende Codeblock ersetzt die Zeichen "/", "@" und "|" durch Leerzeichen, wandelt alles in Kleinbuchstaben um und entfernt alle Zahlen. Mit tm_map(doc, removeWords, c(...) lassen sich häufig vorkommende störende Wörter beseitigen. Anschließend werden noch Satzzeichen und Leerzeichen gelöscht.
Optional lässt sich ein Stemming durchführen, indem das Kommentarzeichen vor der Zeile doc <- tm_map(doc, stemDocument) entfernt wird. Stemming reduziert verschiedene Varianten eines Wortes auf den Wortstamm, etwa "gesehen" und "sah" zu "seh". Da die Wortstämme oft verkürzt sind – so wird "kaufe", "kaufen" und "käufer" zu "kauf" – ist Stemming im Beispiel auskommentiert. Besser wäre eine Zusammenführung auf das Verb "kaufen". Das kann Stemming aber nicht leisten, dazu wäre ein aufwändiges Lemmatizing notwendig. Der Befehl TermDocumentMatrix(doc) wandelt den Text in eine Term-Document-Matrix um. Diese Matrix beschreibt die Häufigkeit von Begriffen in einer Textsammlung. Die Spalten stehen für die Dokumente und die Reihen für die Wörter. Schließlich werden die Informationen in einen Data Frame transferiert. wordcloud() erstellt die Wortwolke. Die Parameter bestimmen die Mindesthäufigkeit und die maximale Anzahl der Wörter sowie den Prozentsatz, in dem die Wörter vertikal angeordnet werden sollen.
warum sieht das bei mir so nicht aus, sondern es werden die Worte abgeschnitten? Liegt das an R?
Ich habe es mit R 3.3.2 erstellt. Möglicherweise verhält es sich mit 4.x anders. Ist der Code identisch zu dem aus dem Blog-Beitrag?